반응형
해당 글은 Python과 Elasticsearch를 연동함에 있어서 나중에 참고를 목적으로 쓴 글입니다.
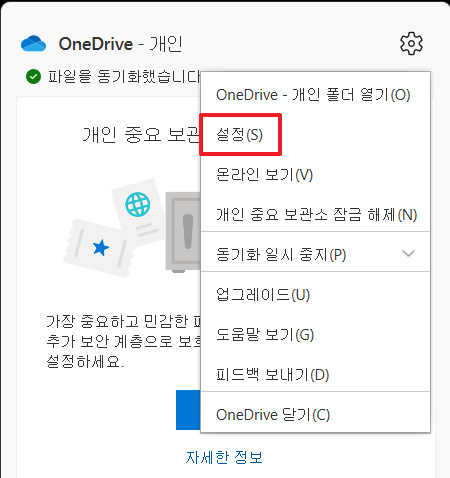
아래 class Elastic() 구현된 기능
1. Elasticsearch 접속 : connect()
2. Index 크기 검색 : count_index_size()
3. 전체 문서 검색 : search_all_docs()
4. 특정 id에 대한 문서 검색 : search_doc_by_risk_id()
# Elasticsearch 관련 모듈 import
from elasticsearch import Elasticsearch
class Elastic:
# Elastic Search 클래스 선언
def __init__(self, host, id, pw):
self.host = host
self.id = id
self.pw = pw
def connect(self):
# connect to elasticsearch
es = Elasticsearch(self.host, basic_auth=(self.id, self.pw), verify_certs=False, ssl_show_warn=False)
if not es.ping():
raise ValueError("ES Connection failed")
print('ElasticSearch 연결 완료')
return es
def count_index_size(self, es, index_name):
# count index size
count = es.count(index=index_name)
index_size = count.body['count']
return index_size
def search_all_docs(self, es, index_name):
# index에 저장된 모든 docs 검색
index_size = self.count_index_size(es, index_name)
search_query = {
# 모든 docs 검색 및 riskid 기준 내림차순 정렬
"sort": [
{
"riskid": {
"order": "desc"
}
}
],
"size": index_size,
"query": {
"match_all": {}
}
}
search_result = es.search(index=index_name, body=search_query)
return search_result["hits"]["hits"]
def search_doc_by_risk_id(self, es, index_name, risk_id):
# index에 저장된 특정id doc 검색
search_query = {
"query": {
"match": {
"riskid": risk_id
}
}
}
search_result = es.search(index=index_name, body=search_query)
return search_result["hits"]["hits"]
if __name__ == "__main__":
# 1. Connect ElasticSearch
elastic = Elastic("https://localhost:9200", "elastic", "elastic_pw")
es = elastic.connect()
index_name = "test_index"
# test_index 내에 있는 모든 문서 검색
all_docs_list = elastic.search_all_docs(es, index_name)
# test_index 내에 risk_id 가 12345인 문서 검색
risk_id = 12345
doc = elastic.search_doc_by_risk_id(es, index_name, risk_id)
caul334@gmail.com
내용이 유용하셨다면 좋아요&댓글 부탁드립니다.
이 블로그를 이끌어갈 수 있는 강력한 힘입니다!
반응형
'IT > Python' 카테고리의 다른 글
| [파이썬] Python 패키지 설치 시 error: externally-managed-environment 에러 (0) | 2025.01.09 |
|---|---|
| [Python] 파이썬으로 특정 폴더 내 다수의 메일 내용 가져오기 (0) | 2024.12.30 |
| [Python] 회사에서 Selenium과 Requests 모듈 사용 시 프록시 적용 방법 (3) | 2024.11.06 |
| [Python] Selenium wire 사용 중 Post 요청 해야하는 경우 (0) | 2024.10.11 |
| [Python] Selenium Wire 사용 시 "주의요함" 메시지 해결 방법 (0) | 2024.10.11 |