반응형
Python으로 Elasticsearch를 연결하려고 하는데 원인을 알 수 없는 이유로 자꾸 연결이 실패한다면...
지금 공유 드린 내용을 테스트 해보세요 그러면 해결 될 수도 있습니다.
Python으로 Elasticsearch를 연결할 때 디버깅 해보니 ID&PW는 맞게 넣었습니다.
하지만 이상하게 연결이 되지 않았는데요 저의 python 소스는 아래와 같았습니다.
문제
def connect(self):
# connect to elastic_search
try:
es = Elasticsearch(self.host, basic_auth=(self.id, self.pw), verify_certs=False, ssl_show_warn=False, request_timeout=60)
if not es.ping():
raise ValueError("ES Connection failed")
print(' - ElasticSearch 연결 완료')
return es
except AuthenticationException as e:
print("인증 실패: 아이디/비밀번호 또는 API Key 확인 필요")
raise e
except ConnectionError as e:
print(f"연결 실패: {e}")
raise e
except Exception as e:
print(f"알 수 없는 오류: {e}")
raise e
해결책
앞으로는 아래와 같이 try문 밑에 elastic 버전을 확인하는 문구를 넣어서 버전을 확인하고 그에 맞게 python 패키지도 설치해줘야 합니다.
try:
es = Elasticsearch(self.host, basic_auth=(self.id, self.pw), verify_certs=False, ssl_show_warn=False, request_timeout=60)
# Elastic Search 버전 확인
info = es.info()
print(info['version']['number'])
만약 elastic 버전이 8.16 버전이라면 python 패키지 명령어는 아래와 같아야 합니다.
> pip install elasticsearch==8.16.0
이와 같이 하니 저 역시 문제를 해결할 수 있었습니다^^

이 글이 도움이 되셨기를 바랍니다.
내용이 유용하셨다면 좋아요&댓글 부탁드립니다.
이 블로그를 이끌어갈 수 있는 강력한 힘입니다!
caul334@gmail.com
반응형
'IT > Python' 카테고리의 다른 글
| Python pip 패키지 오프라인 설치 방법 — 인터넷 없는 환경 완전 가이드 (0) | 2025.09.22 |
|---|---|
| Python으로 Outlook 메일 자동화하기 — MFA·OTP 있어도 되는 방법 (win32com) (0) | 2025.05.23 |
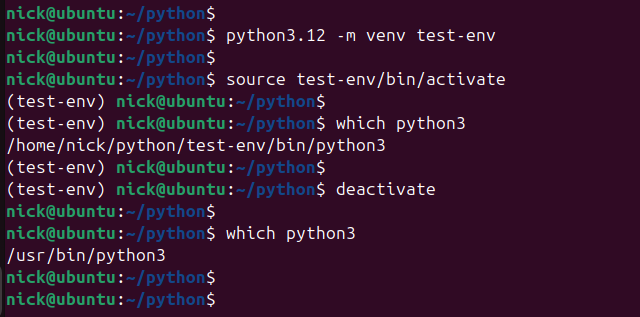
| Python 가상환경 격리 완벽 가이드 — venv, virtualenv 차이와 사용법 (0) | 2025.01.15 |
| Python Poetry 설치부터 기본 명령어까지 — 패키지 관리 완벽 가이드 (0) | 2025.01.14 |
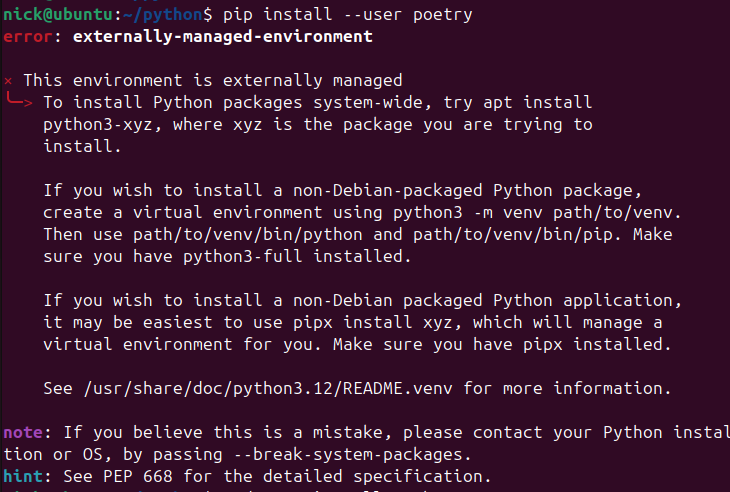
| Python pip 설치 오류 externally-managed-environment 해결 방법 (0) | 2025.01.09 |